
Overview
My favorite method distribution is a direct link to an excel file saved to a SharePoint folder. Its quick to access and if the file is changing daily, then this gives users an easy way to view the most up to date data using the same URL.
Unfortunately, some people just love a good PDF and here we are. The following flow is a reusable child flow that will allow you to export a sheet out of an excel file as a PDF for distribution. Lets get into it.
Flow Time
As we are going to be reusing this flow as a child process, you need to start with a manual trigger and some parameters. This is all built around SharePoint, so if that is not something you are using, then just adapt the parameters as needed.
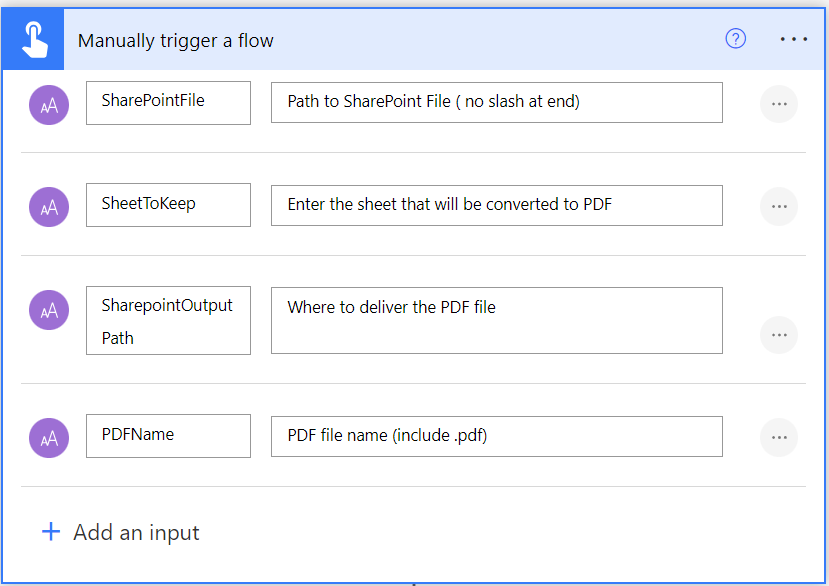
- SharePointFile is the path to the file on SharePoint including the document library
- SheetToKeep is the name of the sheet in Excel that you will be exporting to a PDF
- SharePointOutputPath is the folder location on SharePoint where the PDF will be stored.
- PDFName is the name of the PDF file
Lets jump into our Try scope and start with an excel office script which accepts 2 parameters. wsKeepName which is the sheet we want to export and visibilityType which has two options:
- hidden will hide all the sheets around the one that was specified in wsKeepName
- visible which will unhide all the sheets around the one that was specified in wsKeepName
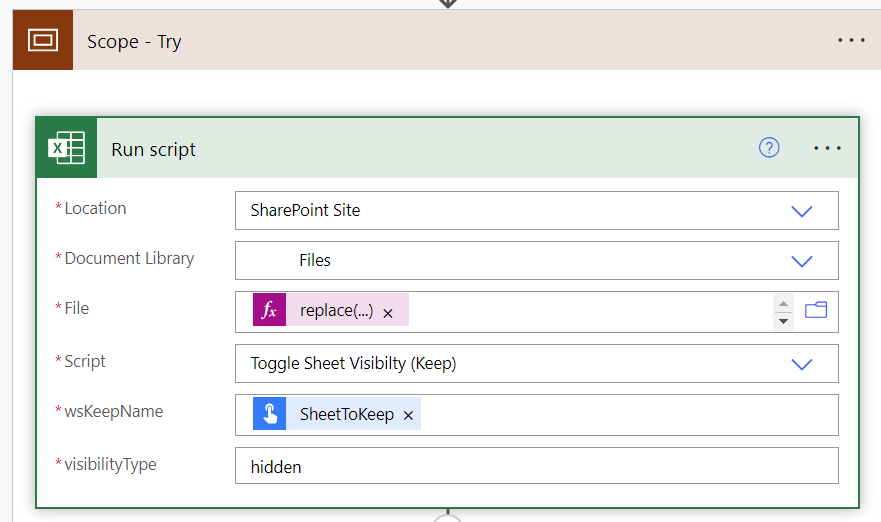
- File:
@replace(triggerBody()['text'],'/Doc Library/','')(This is to remove the doc library section of the path as Excel steps can be inconsistent with this in the path) - Script: This script works by accepting 2 parameters as seen in the screenshot above called wsKeepName and visibilityType
function main(workbook: ExcelScript.Workbook, wsKeepName: string,
visibilityType: string) {
//Assign worksheet collection to a variable
let wsArr = workbook.getWorksheets();
//Create variable to hold visibility type
let visibilityTypeScript: ExcelScript.SheetVisibility;
//Loop through all worksheets in the WSArr worksheet collection
wsArr.forEach(ws => {
//if the worksheet in the loop is not the worksheet to retain
if (ws.getName() != wsKeepName) {
if (visibilityType == "hidden") {
ws.setVisibility(ExcelScript.SheetVisibility.hidden);
}
if (visibilityType == "visible") {
ws.setVisibility(ExcelScript.SheetVisibility.visible);
}
};
});
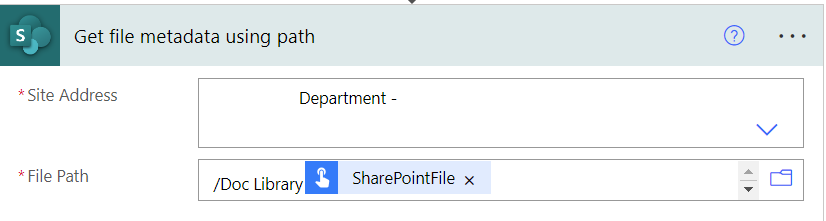
}Next we will get the file metadata of the file we are working with so we can retrieve the itemId field. As there is no way to specify the document library in this step, you need to make sure its in the path as per below.
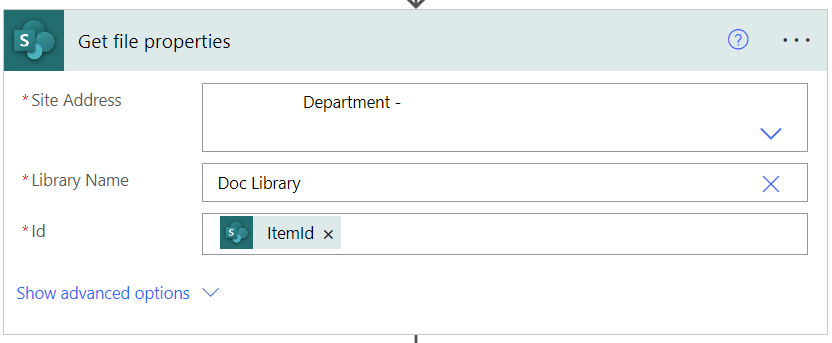
(Optional) Get the rest of the files properties in case we need them.
Now lets get the content of the file so we can write to OneDrive. If you are working only in OneDrive then you can skip a lot of these steps.
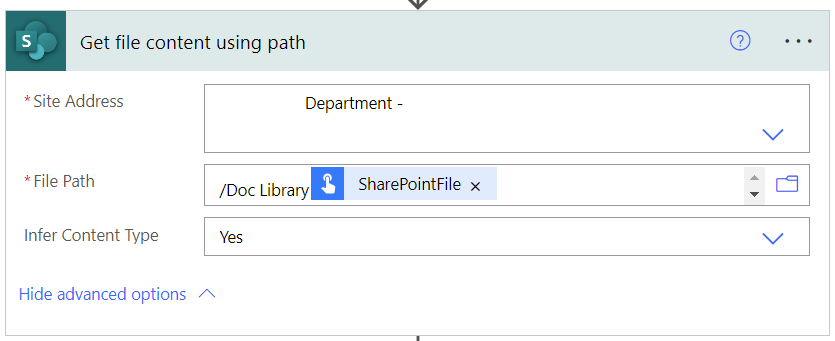
Before we create the file in Onedrive we need to make sure that the old file doesn’t exist so we can reuse the same name. Lets get the file ID so we can remove the file.
You can assign a unique name if you don’t care about having a lot of files in a folder. Up to you.

Now delete the file if its found.

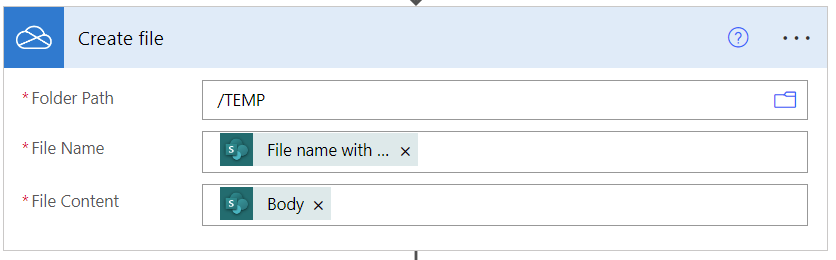
Now create the file.
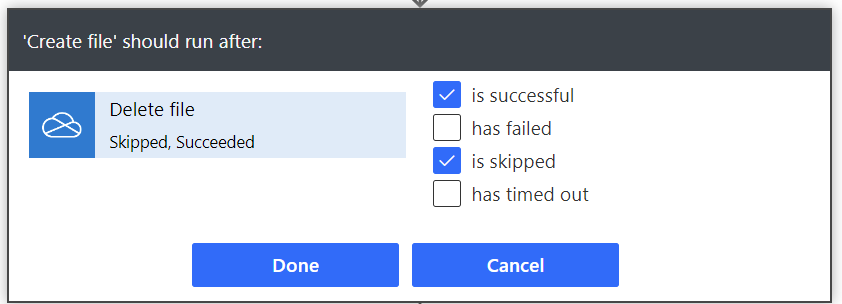
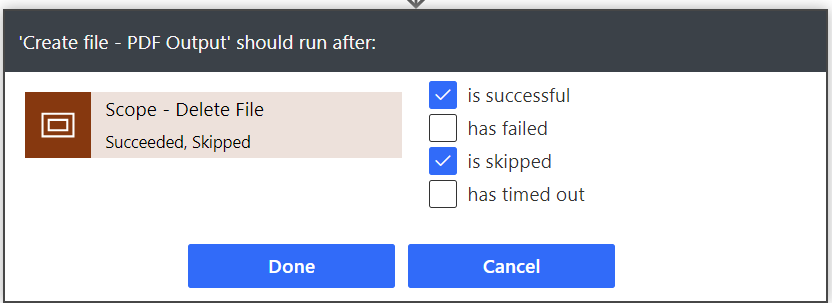
Make sure to configure the “run after” as follows so it doesn’t error out if there is no file to delete.
Here is the important step which creates the PDF. Id is the value that comes from the Create File step.
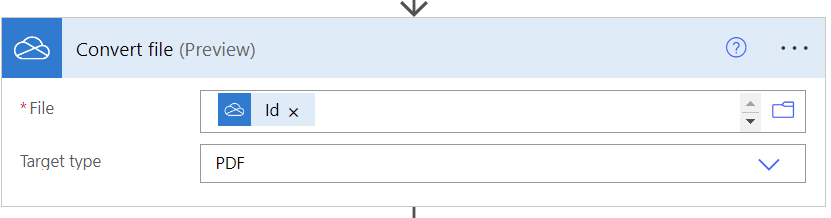
- File: @outputs(‘Create_file’)?[‘body/Id’]
We have now created a PDF of the sheet we specified in OneDrive. If you are using OneDrive as your primary datastore, then you are all set. As i work in SharePoint, there are a few more steps to get the file back for distribution.
Bringing it Back to SharePoint
First we need to check if the output file path provided already exists. You can avoid this all by making it a unique name and adding the time to the end of the provided file name like the example code below but i don’t like clutter. @concat(triggerBody()?['text_2'], '/', replace(triggerBody()?['text_3'], '.pdf', concat('_', formatdatetime(utcnow(), 'HHmmss'), '.pdf')))
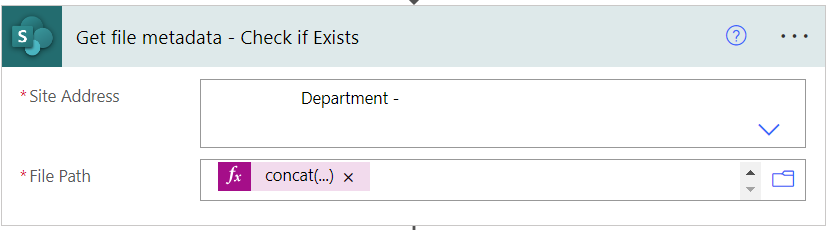
- File Path:
concat(triggerBody()?['text_2'],'/',triggerBody()?['text_3'])
I put the next two statements in a scope so that i can configure a single “run after” control for the entire delete process.
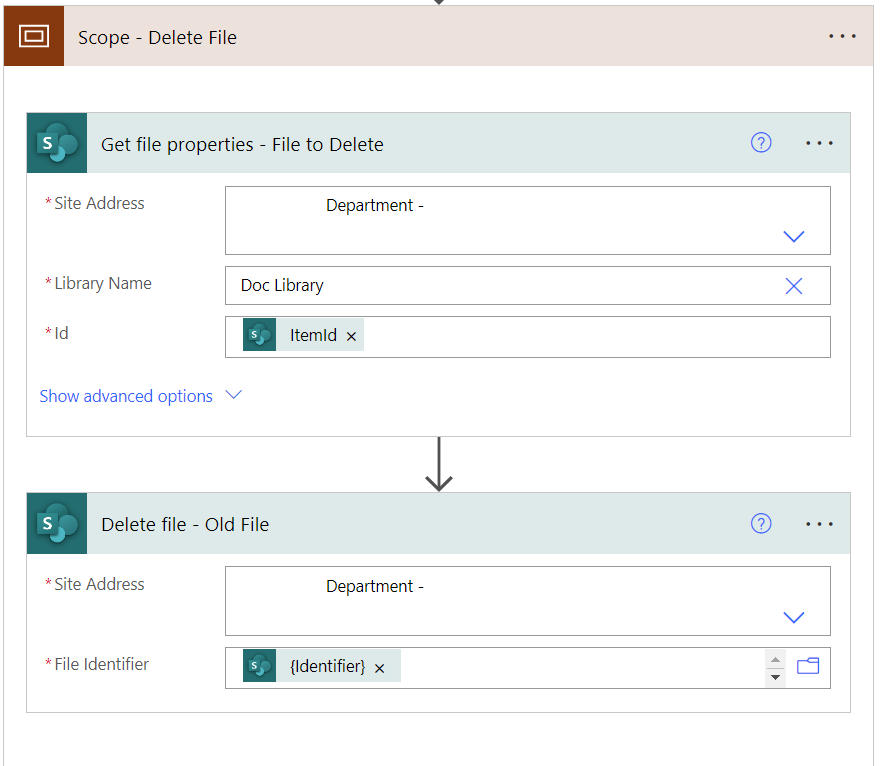
- ID:
@{outputs('Get_file_metadata_-_Check_if_Exists')?['body/ItemId']} - File Identifier:
@body('Get_file_properties_-_File_to_Delete')?['{Identifier}']
Now we can finally create the PDF output. Make sure to configure the “run after” settings to the below.
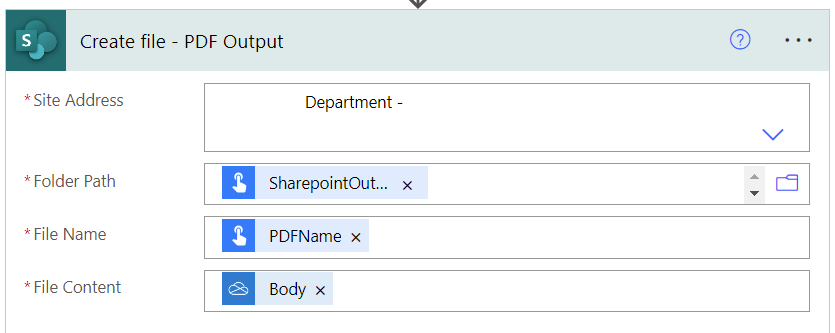
- Folder Path:
@triggerBody()['text_2'] - File Name:
@{triggerBody()?['text_3']} - File Content:
@{body('Convert_file')}
What i like to do is distribute a SharePoint URL to this PDF that has the path hardcoded. Then if i want to update this PDF daily/weekly/monthly, the URL never changes and users can utilize the same link.
As We will be constantly overlaying this file, we need an archive folder to hold historical PDF’s. We just add one more step to create an additional PDF in a subfolder called “Archive”.
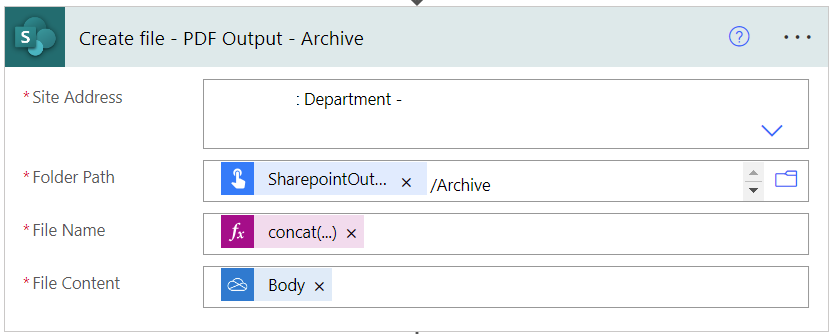
- Folder Path:
@{triggerBody()['text_2']}/Archive - File Name:
@{concat(replace(triggerBody()?['text_3'],'.pdf',''),'_',formatDateTime(utcnow(),'MMddyyyyhhmmss'),'.pdf')} - File Content:
@{body('Convert_file')}
Next we run one this same script again but with different parameters to unhide the sheets we hid earlier.
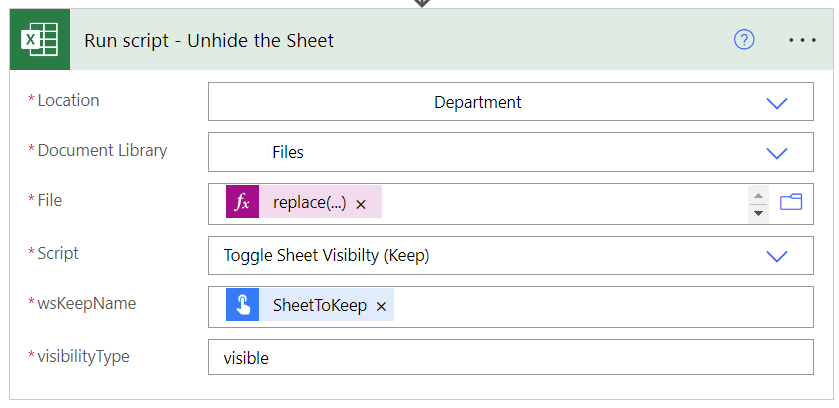
- File:
@replace(triggerBody()['text'],'/Files/','') - wsKeepName: visible
Finally, as this is a reusable flow then we need to end it with a response statement which returns an HTTP status code. Configure this as you wish but you MUST set Asynchronous Response to “ON” or Power Automate will run the process multiple times.
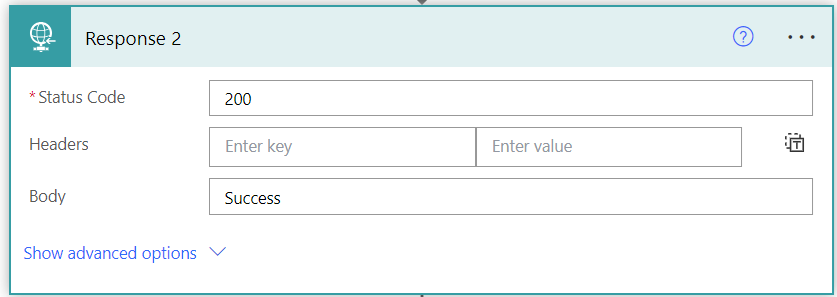
Not sure if this last step is needed but i always add one.

That’s it! Now you can run this process as a child flow from any other flow in your environment. This will let you create a nice PDF file from any spreadsheet you work with.